From a Tree to a Forest: A Guide to Random Forest Algorithm
February 2, 2024

In the previous two posts, we talked about decision trees. The decision trees are very powerful but there is a drawback in them, it causes overfitting issue!
Overfitting is a phenomenon where the model overly adapts to the training data or the data it was exposed to. This makes the model prone to incorrect predictions on unseen data. To be clear, an overfit model is a model which gives high accuracy on training data but low accuracy on testing data.
Since Decision Trees are highly prone to overfitting, Random Forests were introduced. Random Forests are exactly what they sound like. A forest is defined as a collection of trees, similarly a Random Forest is a collection of Decision Trees. But why does it have the term "Random"? Let's find out!
Randomness of Random Forests
The Random Forests split the training data "Randomly" in terms of both rows and features. These uniquely split data is forwarded to each Decision Tree for training them.
The final result produced by the random forest is defines as the class voted by most number of trees in terms of classification and the average for regression problems.
To get the right result without any bias, the data must be random. This way, the model ensures that from most perspectives and combination of features, the produced answer is more accurate.
Building a sample Random Forest
Let is consider the same dataset that we used for Decision Tree Classifier.
| Weather | Temperature | Humidity | Wind | Play Football |
|---|---|---|---|---|
| Sunny | Hot | High | Weak | No |
| Sunny | Hot | High | Strong | No |
| Cloudy | Hot | High | Weak | Yes |
| Rainy | Mild | High | Weak | Yes |
| Rainy | Cool | Normal | Weak | Yes |
| Rainy | Cool | Normal | Strong | No |
| Cloudy | Cool | Normal | Strong | Yes |
| Sunny | Mild | High | Weak | No |
| Sunny | Cool | Normal | Weak | Yes |
| Rainy | Mild | Normal | Weak | Yes |
| Sunny | Mild | Normal | Strong | Yes |
| Cloudy | Mild | High | Strong | Yes |
| Cloudy | Hot | Normal | Weak | Yes |
| Rainy | Mild | High | Strong | No |
Now we create a Random Forest on this data using 3 Decision Trees.
Splitting the Data
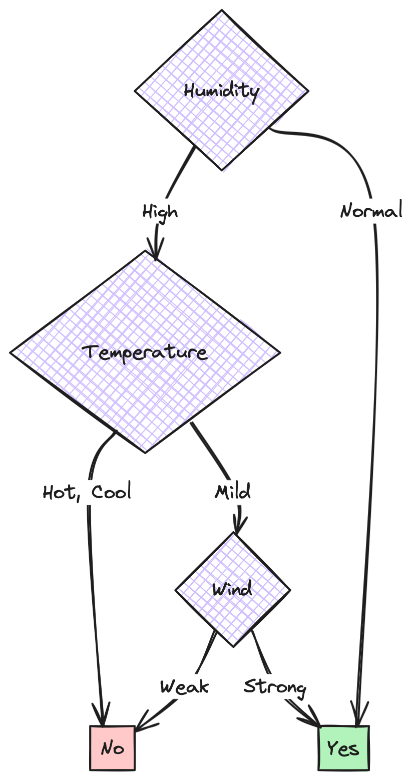
The splitting of data is random. We will randomly select a few rows and any 3 features from the above data for each split.
Split 1:
| Weather | Humidity | Wind | Play Football |
|---|---|---|---|
| Sunny | High | Strong | No |
| Rainy | High | Weak | Yes |
| Rainy | Normal | Strong | No |
| Sunny | High | Weak | No |
| Rainy | Normal | Weak | Yes |
| Cloudy | High | Strong | Yes |
| Rainy | High | Strong | No |
Split 2:
| Weather | Temperature | Wind | Play Football |
|---|---|---|---|
| Sunny | Hot | Weak | No |
| Cloudy | Hot | Weak | Yes |
| Rainy | Cool | Weak | Yes |
| Cloudy | Cool | Strong | Yes |
| Sunny | Cool | Weak | Yes |
| Sunny | Mild | Strong | Yes |
| Cloudy | Hot | Weak | Yes |
Split 3:
| Temperature | Humidity | Wind | Play Football |
|---|---|---|---|
| Hot | High | Weak | No |
| Hot | High | Strong | No |
| Mild | High | Weak | Yes |
| Cool | Normal | Strong | Yes |
| Mild | Normal | Strong | Yes |
| Hot | Normal | Weak | Yes |
| Mild | High | Strong | No |
Building the Decision Trees
The next step is to build a Decision Tree.
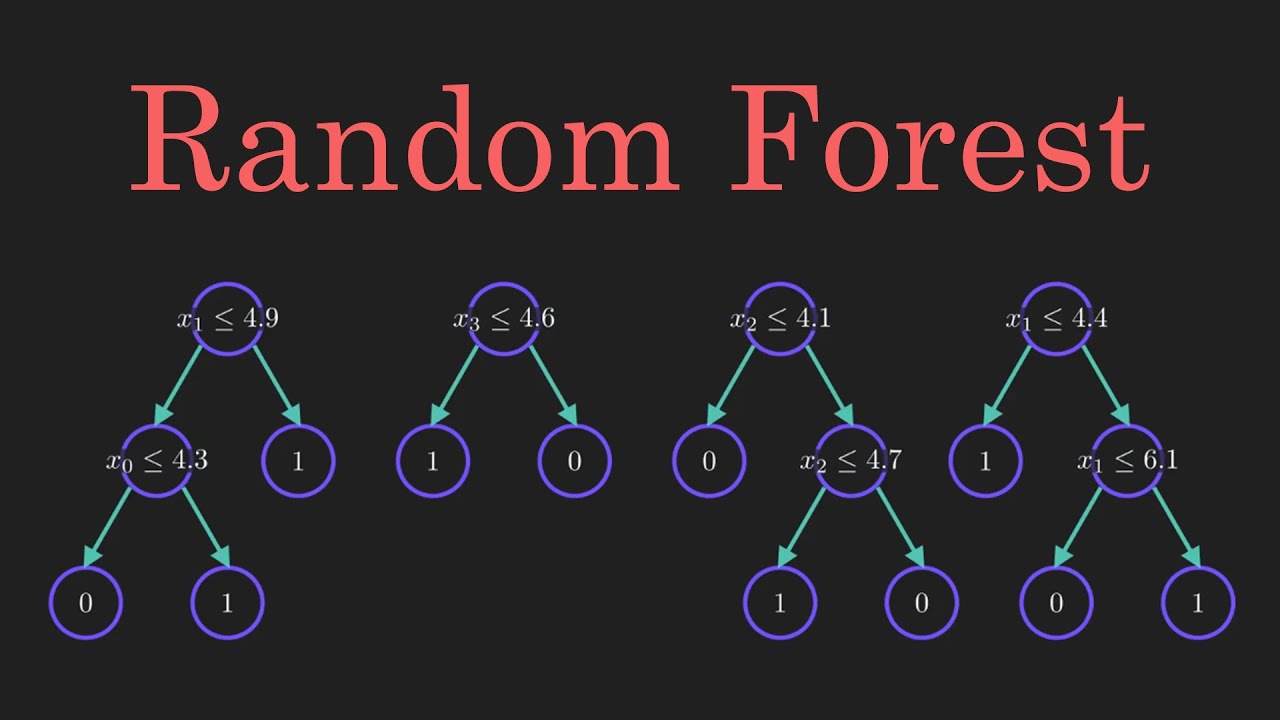
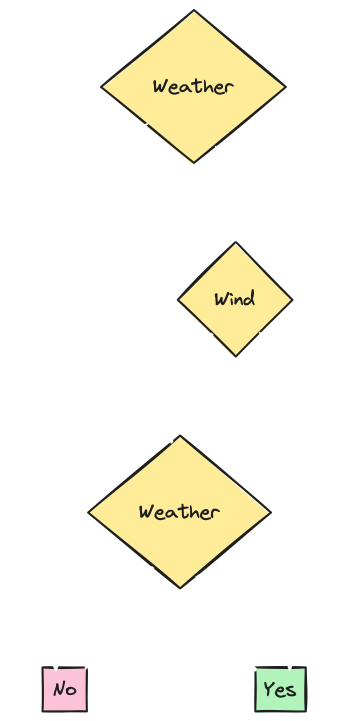
- Tree for Split 1:

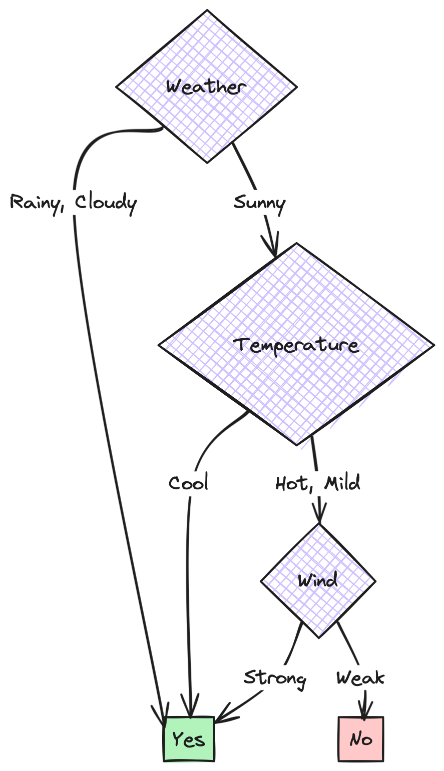
- Tree for Split 2:
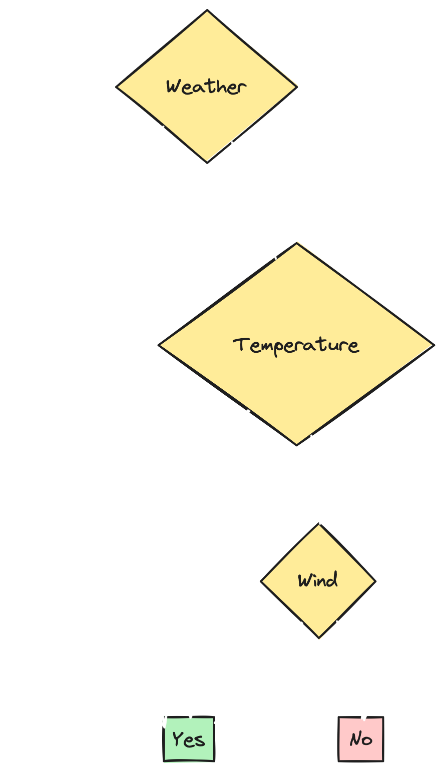
- Tree for Split 3:
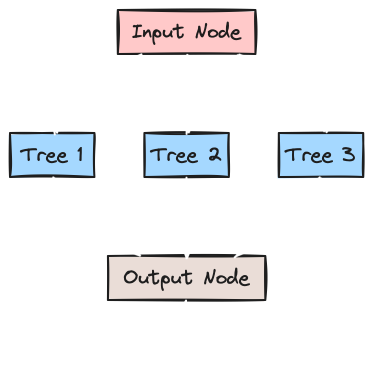
Formation of the Forest
The forest would be a combination network of these trees. The whole data is given as input to the forest. The random forest divides the data into three splits and passes it on to trees. The formed Random Forest will be like this:
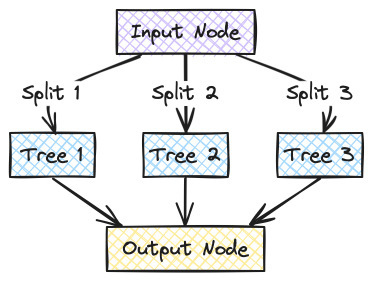

Predicting the Results
The results are not decided by choosing a tree that is most accurate. That would be invalid and cause the overfit issue again. The idea behind Random Forest is to make the prediction based on results of all the decision trees. In Random Forest Classifier, we take the dominant class, i.e., the class predicted by most number of trees. In Random Forest Regressor, we take the average of all the tree outputs.
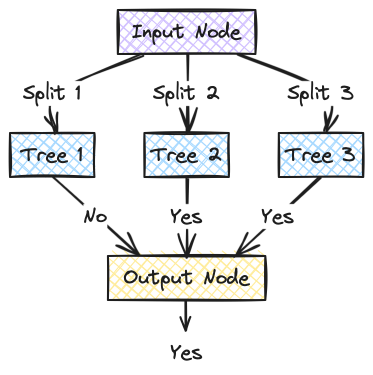
Consider the following example:
- Weather: Sunny
- Temperature: Mild
- Humidity: Normal
- Wind: Strong
The outputs of the above constructed trees would be:
- Tree 1: No
- Tree 2: Yes
- Tree 3: Yes
Since the majority is with "Yes", the random forest concludes with "Yes" as the answer.
This is how it is in the end:
Python Implementation
Let's implement the Random Forest now using the Sci-Kit Learn in python.
# Import required libraries
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Import the dataset and perform required pre-processing
data = pd.read_excel("data.xlsx")
data['Weather'].replace(['Sunny','Rainy','Cloudy'], [0,1,2], inplace=True)
data['Temperature'].replace(['Hot','Cool','Mild'], [0,1,2], inplace=True)
data['Humidity'].replace(['High','Normal'], [0,1], inplace=True)
data['Wind'].replace(['Weak','Strong'], [0,1], inplace=True)
data['Play Football'].replace(['No','Yes'], [0,1], inplace=True)
# Separating Features and Label
x = data.drop("Play Football", axis=1)
y = data[["Play Football"]]
# Split data for Training and Testing
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# Training the model
rfc = RandomForestClassifier()
rfc.fit(x_train, y_train)
# Accuracy Check
print("Training Data Accuracy :", accuracy_score(y_train, rfc.predict(x_train)))
print("Testing Data Accuracy :", accuracy_score(y_test, rfc.predict(x_test)))
# Import required libraries
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Import the dataset and perform required pre-processing
data = pd.read_excel("data.xlsx")
data['Weather'].replace(['Sunny','Rainy','Cloudy'], [0,1,2], inplace=True)
data['Temperature'].replace(['Hot','Cool','Mild'], [0,1,2], inplace=True)
data['Humidity'].replace(['High','Normal'], [0,1], inplace=True)
data['Wind'].replace(['Weak','Strong'], [0,1], inplace=True)
data['Play Football'].replace(['No','Yes'], [0,1], inplace=True)
# Separating Features and Label
x = data.drop("Play Football", axis=1)
y = data[["Play Football"]]
# Split data for Training and Testing
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# Training the model
rfc = RandomForestClassifier()
rfc.fit(x_train, y_train)
# Accuracy Check
print("Training Data Accuracy :", accuracy_score(y_train, rfc.predict(x_train)))
print("Testing Data Accuracy :", accuracy_score(y_test, rfc.predict(x_test)))
The output for the above code is:
Training Data Accuracy : 1.0
Testing Data Accuracy : 0.8
Training Data Accuracy : 1.0
Testing Data Accuracy : 0.8
As we can see, the model performed well. It gave an accuracy of 0.8 on unseen data.
In the next post, we will discuss about the K-Nearest Neighbours Algorithm. Stay tuned!